老周和两次跟 AI 设备的交手
老周的工位在华岳精密第三车间的东北角,挨着一扇朝北的窗。
三十年了,这个位置没换过。1995 年他第一次进厂,带他的师傅就把他放在这里——"调设备的,得靠窗,光线要稳"。那时候他调的是一台德国进口的光学检测仪,要靠肉眼比对投影刻度。后来设备换了五六茬,从机械到电子,从电子到数字,光线这件事倒是一直没变过讲究——老周的工作台上至今还摆着一只 1998 年的色温标定灯,虽然现在派不上什么实际用场,他习惯了它在那儿。
过去三十年,老周干过两种活——调试别人做好的设备,和造厂里需要但市面上没有的专用设备。前者是 80% 的日常,后者偶尔发生,一旦发生就是大活儿——1997 年厂里自研的那台密封圈检测工装、2008 年他带队改装的那台在线测量系统、2019 年他主持设计的那条异形件视觉分拣线——都是他从图纸开始一点点磨出来的。
他没想到,去年秋天开始,他又要把这两种活儿重新干一遍。只不过这一次,手里的"设备"换了个东西。
第一次交手:调一台别人做好的 Agent

去年秋天,厂里一条新的视觉质检产线上了一个缺陷识别 Agent。供应商是一家做 AI 的初创公司,模型基于某个开源视觉大模型微调而来。产线连调那两周,供应商的技术团队来厂里驻场——两个戴眼镜的年轻人,带着三台笔记本电脑和一堆云平台账号,说着老周听不太懂的词:"召回率"、"F1"、"embedding"、"prompt 版本"。
调完那天,产线能跑了,合格品识别率 97%。供应商收了钱走人。临走之前年轻工程师问:"你们厂里谁负责这套系统的日常调试啊?"
郑总站在旁边说:"老周。"
老周愣了一下。他以为自己早就退出调试一线了——最近几年他主要带徒弟,调设备的活儿交给下面人干。但郑总的意思很清楚:这不是一台普通设备,厂里没人比老周更会"跟设备较劲"。
那天下午,两个年轻工程师留给老周一个 U 盘、一份操作手册、一个微信群。
"老师傅,以后有问题群里 @ 我们。"
老周接过 U 盘,点点头。
调试的第一个月,老周把这个 Agent 当作一台新设备来摸底。
他的习惯是——任何新设备进厂,先做三件事:抄参数、跑基线、记异常。
抄参数这件事让他第一次懵了。过去所有设备都有一份"技术规格书"——电压、电流、工作温度、精度、寿命、故障率。这台 AI 设备的"规格书"长什么样?他翻遍供应商给的资料,找到的是一份"模型卡":基座模型版本、训练数据集描述、推理 API 接口、支持的图像格式。但没有一个数字能告诉他——这设备在 97% 的识别率之外,剩下 3% 错在哪里。
他去群里问。供应商工程师回了一句:"这个要看具体 case,大模型的错误模式比较复杂。"
老周心里咯噔一下。三十年调设备的经验告诉他——一台连"故障模式"都说不清楚的设备,是不能进关键工位的。这句话他没在群里说出来。但他当晚回家,翻出了自己用了三十年的那本泛黄的设备病历本——每一页对应一台设备,记录它的"脾气"、它容易坏的地方、它在什么天气下会飘。本子最后一页还剩三行空白。
他翻到第一个空白页,用钢笔写下:
2025 年 10 月 17 日,视觉质检 Agent,代号 V-1
基座模型:某某视觉大模型 v2.3 验收合格率:97% 未知故障模式。
"未知故障模式"这几个字,他写得特别重。
跑基线是第二件事。
老周按自己的方法,从厂里历年的合格品和不合格品库存里挑了 1000 个样品——其中 850 个是明确合格的标准件,150 个是各种典型缺陷的废品。他把这 1000 个样品一个一个喂给这台 Agent,记录每一次的识别结果。
这个过程花了他三天。第三天晚上,他对着记录表看了很久。
整体准确率和供应商说的差不多,97.2%。但他发现了几件让他不舒服的事。
第一,同一个样品,连续喂三次,Agent 有时候会给出不同的判断。一个边缘有轻微毛刺的零件,第一次判"合格",第二次判"不合格",第三次又判"合格"。整个过程他没有动样品,没有动光线,什么都没动。Agent 自己"飘"了。
第二,Agent 对某一类缺陷的识别明显弱于其他类——表面划痕类识别率 99%,但"装配间隙偏大"这类几何偏差的识别率只有 82%。供应商给的 97% 是平均值,这个平均值掩盖了一件事——设备在某些场景下是不合格的。
第三,最让老周不安的一件事——有一个明显的废品(螺纹严重错牙),Agent 判了"合格",而且判断置信度 0.94。这个置信度如果在产线上会被自动放行。老周盯着那个数字看了很久。
他回到病历本,在那页下面继续写:
10 月 20 日,基线测试 1000 件。
整体准确率 97.2%,但存在三个严重问题:
输出不稳定。同一样品多次识别可能给出不同结果。
能力不均衡。不同缺陷类型识别能力差异 17 个百分点。平均数掩盖了真实的能力边界。
高置信度错误。错判的同时给出高置信度——这是最危险的一类故障,因为它骗过了下游判断。
结论:这台设备目前不具备独立进入关键工位的条件。
他把这份记录发给了郑总。
郑总第二天早上来找他,带着两个年轻工程师。年轻工程师看完记录,有点不自在地说:"老师傅,这个……AI 模型本来就有概率分布,不能完全消除随机性。"
老周没抬头,只说了一句:"能跑起来不算数,能稳定跑一年才算数。"
这句话后来在厂里传开了。
从那天起,老周开始正式把这台 Agent 当成一台"新型号设备"来摸。他给自己定了三个规矩。
第一,把"不确定性"当作设备参数来管。他要求供应商每次模型更新后,重新跑一次他那 1000 个样品的基线测试,记录每一类缺陷的识别准确率、置信度分布、不稳定率(同样品多次识别结果不一致的比例)。这些数字成为这台设备的"参数手册"——和电压电流同样严肃的那种参数。
第二,建立"故障模式库"。每一次 Agent 出错,老周都会把错判的样品单独存起来,标注错误类型。三个月下来,他建了一个 87 个样品的"故障模式库"——里面每一个都是这台 Agent 目前搞不定的场景。这个库有两个用处:一是验收新版本的时候必测,新版本不能在老故障上倒退;二是遇到新场景评估风险时,可以先看一眼库里有没有类似模式。
第三,划清"能跑"和"能上"的边界。有些场景这台 Agent 的表现已经可以,比如表面划痕识别;有些场景还不行,比如几何偏差识别。老周的做法是——按场景分级授权。划痕识别这类 Agent 可以独立判断,放行产品;几何偏差类必须有人工复核,Agent 只给建议。
他把这套东西写成一份四页纸的文件,标题叫《V-1 视觉质检 Agent 运行规范》。郑总看完,让技术部按这份规范立即实施。
供应商的年轻工程师看到这份规范时,愣了一下。他说:"老师傅,您这套东西,其实就是我们搞 AI 的那套 evaluation 和 deployment policy……但说实话,我们自己内部都没做得这么细。"
老周"嗯"了一声。"我们厂里 1997 年第一台进口加工中心,也是这样磨出来的。你们 AI 再新,它也是台设备。"
第二次交手:从零造一台 Agent
V-1 摸清楚之后,厂里安静了一阵。但老周知道这只是开始。
春节后不久,郑总找他喝茶。
"老周,开年有个事儿要你牵头。"
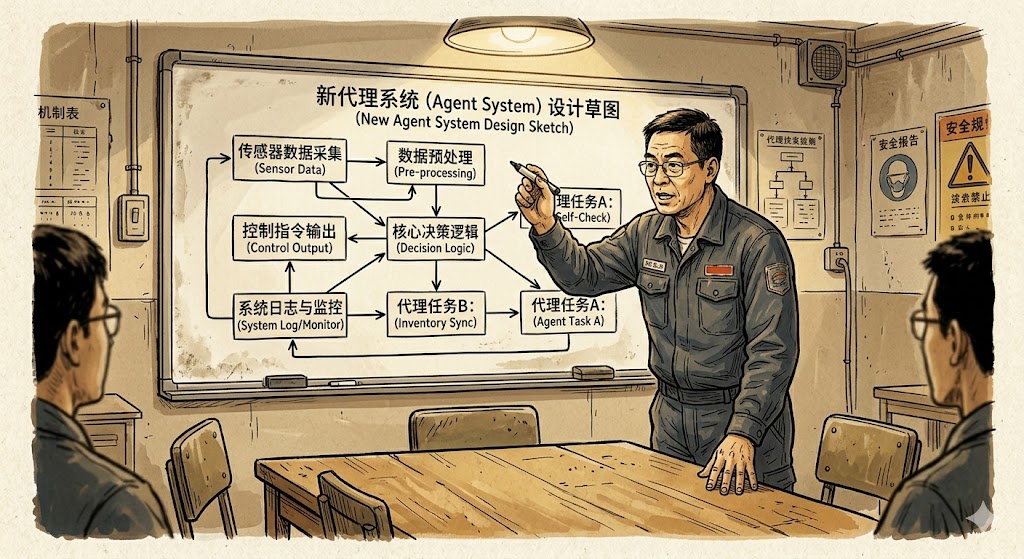
郑总说的是一条新产线——厂里接了一个大客户的定制化订单,订单种类多、规格杂,传统的人工接单和排产已经顶不住。厂里决定上一个智能订单处理 Agent:客户发来订单文件(PDF、邮件、甚至微信聊天截图都有),Agent 要自动识别型号规格、匹配厂里的产能和物料库存、生成排产建议、给出报价和交期。
"这次没有供应商。"郑总说。"市面上没有专门做我们这行的方案。厂里 IT 部能搭框架,但懂业务的人得是你。老周,这台'设备',你来牵头造。"
老周没立刻答应。他抽了半根烟,说了一句:"让我先想想这台设备的'设计图'长什么样。"
那天晚上回家,老周在病历本上翻到 1997 年那一页。
1997 年,他带队造厂里第一台自研密封圈检测工装。那一页记录着整个过程——需求拆解、功能分解、选型、打样、测试、验收、分级投产。每一步他都写得清清楚楚,二十八年过去字迹还很清晰。
他盯着那一页看了很久,然后翻到病历本的中后段,开始写新的一页:
2026 年 3 月,订单处理 Agent,代号 V-2(规划中)
参照 1997 密封圈工装造法,分七步走:
需求拆解:搞清楚这台"设备"到底要完成什么任务。
功能分解:把大任务拆成 Agent 能分别做的小动作。
选型:基座模型、框架、工具链,一项一项定。
打样:先做一个最小可跑的版本,在小批量订单上试。
测试:按 V-1 那套规矩,跑基线、建故障库。
验收:定准入准出标准,不达标不上线。
分级投产:从低风险订单开始,逐步扩大范围。
这套步骤和他 1997 年造密封圈工装的逻辑几乎一样——只是零件换了。
过去的"零件"是传感器、光源、夹具、PLC、伺服电机。
现在的"零件"是:基座模型(大模型选型:规模多大、上下文多长、工具调用能力如何)、数据来源(厂里的订单历史、产能数据、物料库存接口)、prompt 结构(任务描述、约束条件、输出格式)、工具调用(查库存、算产能、生成报价单)、上下文管理(多轮订单澄清怎么维护对话状态)、编排框架(几个子任务串起来用什么工具)、故障兜底(Agent 处理不了的订单怎么转人工)。
零件不一样了。但"造一台设备"的工序逻辑,没变。
接下来的两个月,老周按这七步一步一步推进。
需求拆解花了他最久的时间。他跟销售部、排产组、物料组、财务开了六次会,最后搞清楚一件事——这台 Agent 真正要干的不是"处理订单",是"在信息不全的情况下,给出一个敢拍板的报价和交期"。过去这件事人来做,做得好的销售靠经验和感觉;Agent 要把这套经验和感觉变成可描述、可验证、可改进的逻辑。
功能分解之后,他列出了这台 Agent 需要的 7 个子动作:文件解析、规格识别、库存查询、产能匹配、报价计算、交期估算、结果复核。每个子动作背后对应一个"零件"——有些用大模型、有些用传统脚本、有些调外部 API。
选型阶段他做了一件让 IT 部很意外的事——他坚持要求"每个子动作都用最简单够用的零件,不许过度设计"。"规格识别"这一步,有人建议用一个带 vision 能力的大模型,老周说不行,"我们的订单 90% 是文本 PDF,用 vision 模型又慢又贵,OCR 加规则匹配就够了。剩下 10% 非标情况再用大模型兜底。"——这个决策后来被证明是对的,上线后单次订单处理成本比最初的方案低了 60%。
打样阶段他坚持让 Agent 先只处理一类最简单的订单——"标准件单规格小批量"。不贪多、不做全。郑总那段时间问过他:"这么小的范围,值得立项吗?"老周的回答是:"先让这台设备能稳定跑通一种规格,再说下一种。我 1997 年造密封圈工装,第一台也只能检一种规格。"
到了测试阶段,老周把 V-1 那套方法几乎原样复用过来——跑 1000 个历史订单做基线、建故障模式库、记录"设备飘移"情况。
他发现了一个有意思的现象:V-2 的"飘"和 V-1 不一样。V-1 是视觉模型,飘的时候是"看走眼";V-2 是语言模型,飘的时候是"想偏了"——同一个订单,两次解析可能把不同字段识别成型号。老周给这种新的飘移起了个名字,叫"语境漂移",记在了病历本上。
验收他定了硬指标:基线测试的 1000 个历史订单,Agent 处理结果和人工处理结果的一致率必须达到 95% 以上;"高置信度错误"(Agent 自己很确定但实际搞错了的情况)必须低于 0.5%;每次模型或 prompt 升级,必须在这 1000 个订单上重新跑一遍,回归不倒退。
分级投产他设了三档:独立处理档(标准件订单,Agent 直接出报价)、建议档(非标但有历史记录的订单,Agent 给建议,人审核后放行)、转人工档(全新客户、超大额、涉及特殊合规的订单,Agent 一律转人工)。这个分级结构后来被厂里其他 Agent 项目照搬。
V-2 上线那天,没有剪彩,没有仪式。老周照例跑了一遍那 1000 个订单的基线,记录在病历本上:
4 月 15 日,V-2 订单处理 Agent 投产。
基线一致率 96.3%。高置信度错误率 0.2%。 初期仅开放"独立处理档"订单,约占总订单量 35%。 剩余 65% 走"建议档"和"转人工档",按月评估扩展。
第一次不是调试别人的设备,是造自己的。 工序没变,零件换了。
那天下午,郑总来车间转了一圈。他看了看老周的记录,说了一句:"老周,这台设备造得像样。"
老周笑了笑,没说话。
晚上回家之前,老周在病历本的扉页上加了一行字。
之前那里写着:"设备更换了几代,但设备这两个字,还没换。"
这次他在下面又加了一行:"会造设备的人,比会用设备的人,永远少一个数量级。"
V-2 之后,老周的工作越来越忙。厂里陆续开始立项新的 Agent——有的是调试已有方案,有的是从零设计。每一次新项目启动,郑总都会把老周拉进来。那本泛黄的病历本,现在已经记到了第 23 页——V-1、V-2、V-3(产线异常分析)、T-1(文档处理主 Agent)、S-1 到 S-12(一串老周带人造的支持 Agent)……
老周办公桌上那只 1998 年的色温标定灯,还在原来的位置。三十年没换。
相关手记
郑总 55 岁,从基层干到副总。他不写代码,但要决定工厂怎么建 AI——什么时候招什么人、每月 token 烧多少钱、哪些 Agent 的 ROI 为正。前面七个工位的故事在这里汇合,他要拼出一座能算清账的工厂。
吴师傅 58 岁,精密装配的"手艺人",三次自动化都没替代的异常判断高手。技术团队找他帮贷款审批 Agent 设计人工复核节点——他们假设"AI 能做的都交给 AI",吴师傅的标准是"出错了谁负责、谁能兜住"。
小刘盯仪表盘三年。厂里 Agent 系统上线两个月没人做可观测性——他不知道哪个 Agent 每天烧多少钱、什么时候会挂。他用两周自己拼了块仪表盘,上线第一天就发现了一个没人注意到的问题。
