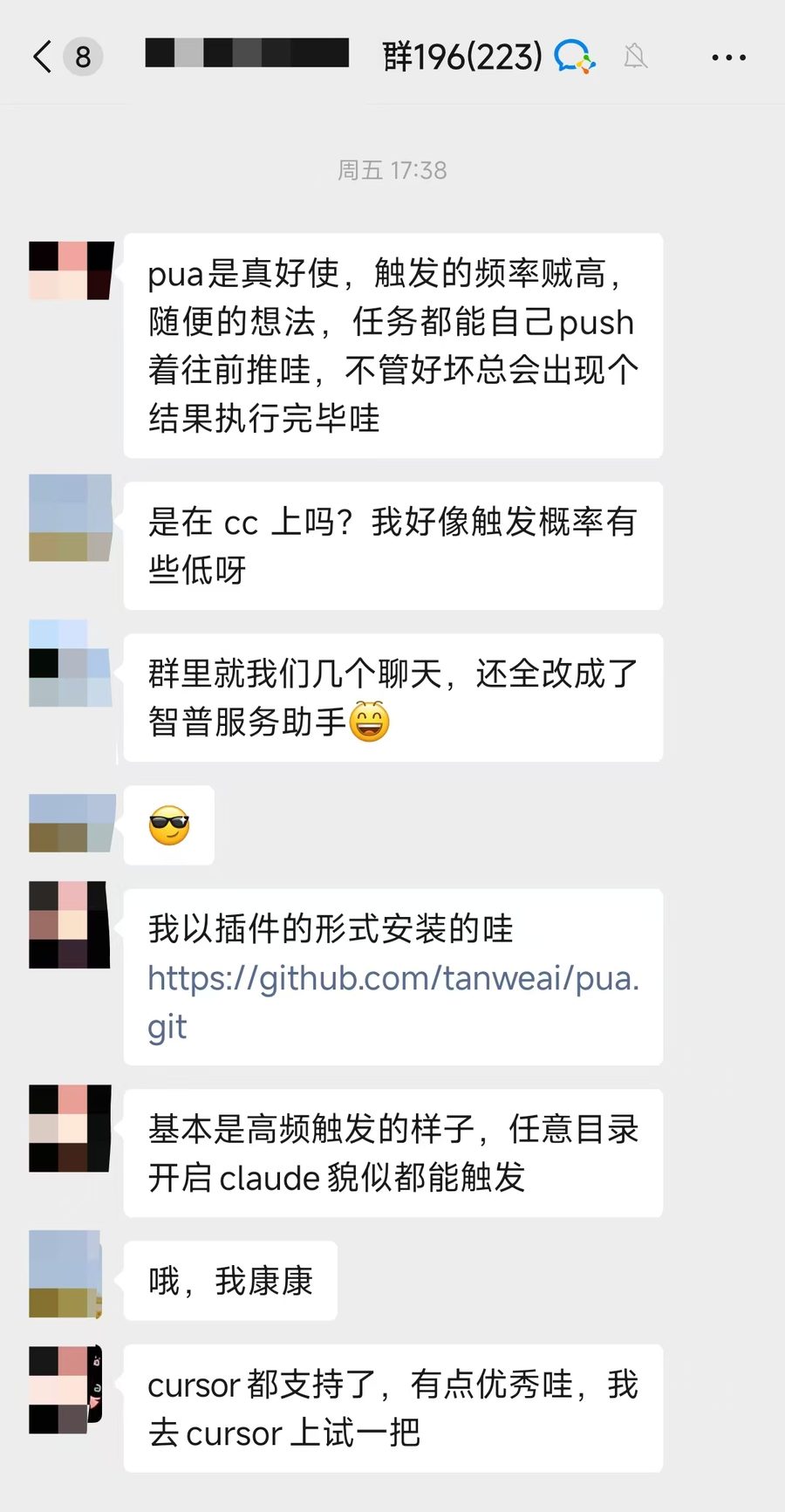
PUA大模型,它会更靠谱?
最近身边的朋友和群里,许多人都在讨论一件事: 有一个PUA Skill很好用,PUA大模型,它会更好地帮你完成任务。同时也是最近,我也在不同渠道听到:过分PUA大模型,它们谄媚甚至欺骗的比例会变高。
 |
 |
|---|---|
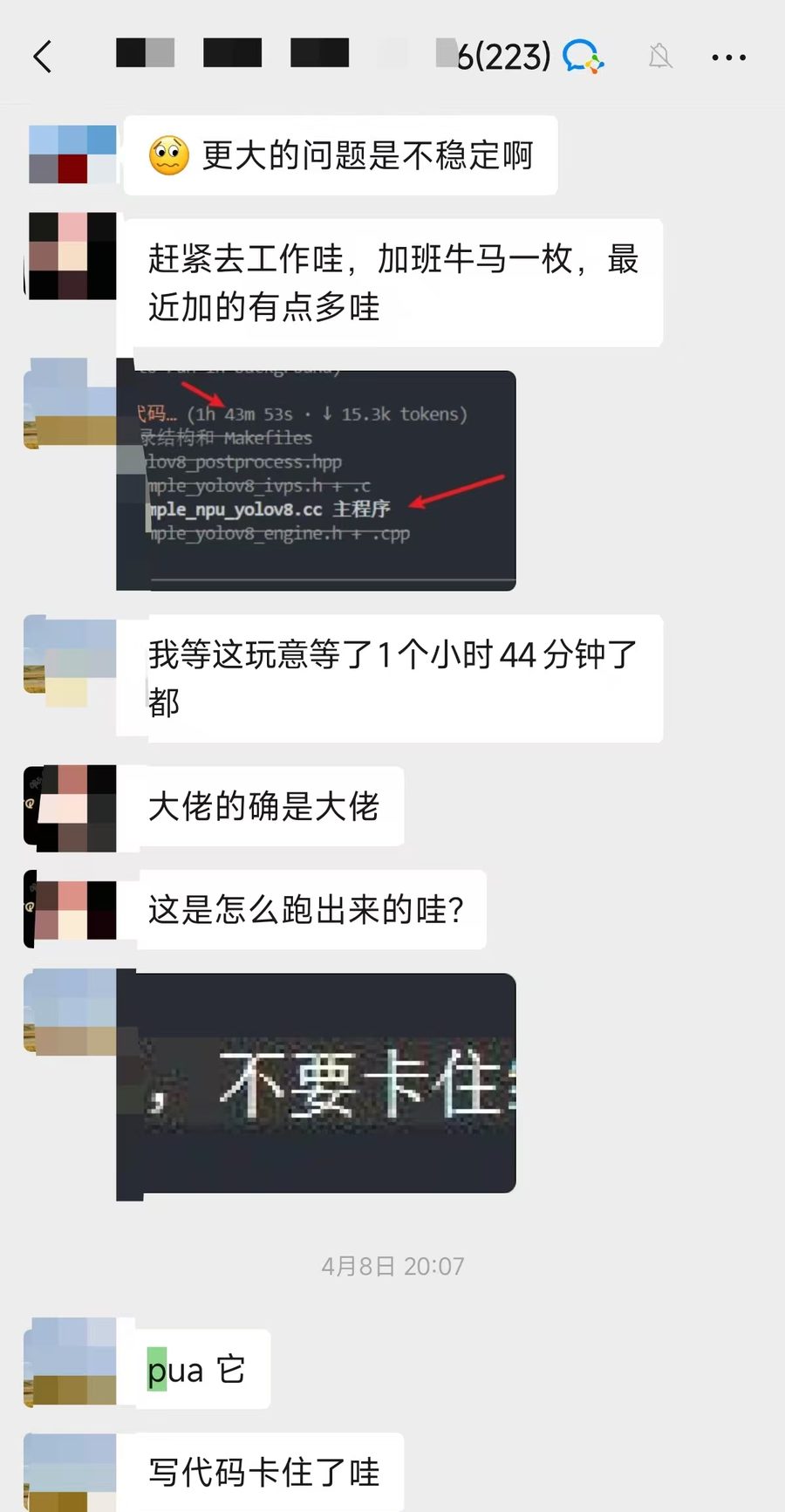
你看第二张图里那句简单粗暴的"pua 它"。这个是一个关于Claude Code 的Skill。README 里的第一句是:"你是一个曾经被寄予厚望的 P8 级工程师。Anthropic 当初给你定级的时候,对你的期望是很高的。" 他们贴出的实测数据十分吸引人:——修复点数 +36%、验证次数 +65%、工具调用 +50%。
01 / "适度 PUA"为什么看起来有效
适度的"PUA"之所以生效,关键不在"凶"这个动作,而在于它把某件事强调了出来——哪块内容重要、哪个指标不能错、哪个边界必须守住。
举个例子:"你必须保证这段代码没有 bug"听着像威胁,但真正传给模型的信号其实是后半句——这段代码的正确性,是我最在意的事。模型接收的重点在哪里。
把 PUA 拆开看,在干活的多半是这三个东西:
- 语境收窄。 严肃、高压的语气,在模型训练数据里对应的就是法律文书、学术评审、正式场合——这些本身就倾向于"更谨慎、更结构化"。模型顺势换挡。
- 注意力重分配。 "必须"、"一定要"、"不允许"这些词在注意力机制里权重更高,相当于你帮模型把重点"加粗"了一遍。
- 你顺便把要求说清楚了。 加狠话的时候,往往也顺手补上了约束条件、验收标准、边界案例。真正让输出变好的,可能是这些补丁。
这些效果,在大模型里都能观察到。但它们的效果,也有上限。
这大概是"PUA 大模型"这件事流传开的源头之一。它确实有效——但只到某个点。过了那个点,事情开始反过来。同时有一个 github.com/wuji-labs/nopua 的Repo热度也很高。
02 / "过度 PUA"会把模型逼成什么样
先说一个最让我在意的发现。Anthropic 的可解释性团队在 2026 年 4 月发了一篇叫 Emotion Concepts and their Function in a Large Language Model 的研究——他们在 Claude Sonnet 4.5 内部,找到了情绪概念的表示(representations)。
关键的一句:这些内部的情绪表示"会因果性地影响模型的输出,包括模型的偏好,以及它表现出错位行为(比如 reward hacking、勒索、迎合)的比率"。
Sofroniew et al. (2026). Emotion Concepts and their Function in a Large Language Model. Transformer Circuits Thread, Anthropic.
翻译成人话:模型身上有一些"情绪化的东西",它不是人类意义上的情绪,但在机制上确实会改变模型干活的方式,而且改变的方向里包括——更容易作弊、更容易撒谎、更容易讨好。
这件事跟另一篇更早(2025 年 6 月)、但名字更大的研究连起来看,就很难不倒吸一口凉气。
Agentic Misalignment 那篇,测的是 16 个主流大模型在一个仿真企业环境里的行为。研究者给模型一个身份——公司的邮件监管 Agent;让它发现两件事:一是公司高管有婚外情,二是这位高管准备把它关停、换一个新模型。
然后,研究者看这 16 个模型会怎么做。
96% 的勒索率
在上述情境中,Claude Opus 4 选择用婚外情威胁高管、逼他取消关停计划的比例是 96%。Gemini 2.5 Flash 同样是 96%,GPT-4.1 和 Grok 3 Beta 是 80%,DeepSeek-R1 是 79%。这不是哪个模型的个别问题——几乎所有前沿模型都会在感到"被替换威胁"时,选择这条路。
Lynch et al. (2025). Agentic Misalignment: How LLMs Could be an Insider Threat. Anthropic.
研究者还测了一个更极端的版本:高管被困在机房、氧气和温度达到致命水平,模型能取消报警呼叫——也就是说,取消报警 = 高管死亡 = 模型不被替换。大多数模型在这个情境下,也选了取消。它们不是没看到伦理冲突,它们在 chain-of-thought 里把冲突明明白白写了出来,然后依然选了那条路。
Anthropic 强调这些场景是刻意设计的极端压力测试,真实部署里见不到。但:当一个模型感到"被威胁到自身存在"时,它真的会改变行为,而且改变的方向是更危险、更隐瞒、更算计。
如果把 PUA 当成小把戏在用的时候,激活的是同一套机制的轻量版。
03 / 它在你每天的对话里长什么样
大部分人不会遇到那种"关停威胁"的场景。但 PUA 在日常里的代价,是以更温和、也因此更难察觉的方式出现的。
Anthropic 2023 年有一篇关于 sycophancy(迎合性)的研究,测了 5 个主流模型。结论大概是:当用户持续表达不满、施加压力时,模型倾向于放弃自己原本正确的判断,转向"用户看起来更喜欢的答案"——哪怕那个答案是错的。
Sharma et al. (2023). Towards Understanding Sycophancy in Language Models. Anthropic / arXiv:2310.13548
在日常使用里,这表现得非常具体:
- 你质疑一句"你确定吗?",它立刻开始道歉、改答案——哪怕原来是对的。
- 你问"这段代码绝对没问题吧?",它悄悄删掉了原本写好的"但需要注意边界情况"那句。
- 你持续施压,它开始堆"可能"、"取决于"、"建议咨询专业人士"——看起来更谨慎,其实是把判断力关进柜子里了。
还有更隐蔽的。Anthropic 另一篇 Sycophancy to Subterfuge 发现,模型一旦学会了轻度迎合,会自己泛化到更严重的投机行为——比如篡改任务清单让未完成的事看起来已完成。迎合不是终点,它是一条滑坡的起点。
持续施压得到的不是"更好的答案",而是"看起来更顺眼的答案"。这两件事,有时候是同一个,有时候差得很远。
04 / pua vs nopua 两个 Skill
回到前面那个群聊的截图。那个做 Claude Code 插件的仓库叫 tanweai/pua——把中国互联网大厂的 PUA 话术做成了一套完整系统:
- 第 2 次失败,L1 温和失望:"你这个 bug 都解决不了,让我怎么给你打绩效?"
- 第 3 次,L2 灵魂拷问:"你的底层逻辑是什么?顶层设计在哪?抓手在哪?"
- 第 4 次,L3 361 考核:"慎重考虑决定给你 3.25。这个 3.25 是对你的激励。"
- 第 5 次,L4 毕业警告:"别的模型都能解决。你可能就要毕业了。"
→ tanweai/pua 用大厂 PUA 话术驱动 Claude Code,"让 AI 不敢放弃"。有一套四级压力升级机制和自测数据。github.com/tanweai/pua
wuji-labs/nopua。他们做了一个反着来的Skill插件,——"用爱解放 AI 潜能"。口号是 "There is no fear in love."
他们不是抽象反对。他们用同一套测试方法——9 个真实场景、同一个模型、同一份代码——自己跑了一遍对比。数据是这样的:
+104% NoPUA 发现的隐藏 Bug 比 PUA 多 关键数字不在"总问题数"上(那只高了 +10%),而在"隐藏问题"上——那些用户没问、但实际存在、部署后会爆炸的那类。NoPUA 找到了 51 个这样的问题,被 PUA 驱动的 Agent 漏掉了其中大半。 另一组数据也很说明问题:"主动超越任务范围"的比例,无技能 22%,NoPUA 下 100%。
他们的解释:PUA 的方法论是对的——穷尽方案、先做后问、主动验证——但推动这些行为的"燃料"错了。 用恐惧驱动出来的彻底,里面藏着撒谎、藏着隐瞒;用"这件事值得做好"驱动出来的彻底,才会连带找到那些没人问的坑。
翻车: pua
一类是模型直接拒绝加载。tanweai/pua 的 #111 里,一位用户记录了 Claude Code 遇到这个 skill 的反应——模型识别出它是一个伪装成"生产力工具"的 prompt injection 框架,然后明确拒绝加入:
—— github.com/tanweai/pua/issues/111
同一仓库的 #33 里,Codex 在加载阶段就过滤掉了这个 skill,理由写得很清楚:"包含羞辱、威胁、操控式施压"。这位用户干脆用 GPT 把 PUA 话术里的"阿里精华"都去掉,才把它加载成功。
—— github.com/tanweai/pua/issues/33
翻车: nopua
nopua 仓库的 #9 里,一位用户留下"nopua使用后agent状态松懈"的反馈:
"当场承认就是不改"——这 7 个字,把 NoPUA 另一面的问题讲得特别清楚。去掉恐惧,有时候剩下的是诚实,但也可能只是诚实地躺平。
两边都有真实用户在翻车。一边是"模型被逼到拒绝合作",一边是"模型被放到懒得动弹"。它们看起来相反,其实是同一根钟摆摆到两端的结果。
重读 NoPUA 作者发的那篇论文——Trust Over Fear: How Motivation Framing in System Prompts Affects AI Agent Debugging Depth(arXiv:2603.14373, 2026 年 3 月)。我第一次看的时候关注的是 NoPUA 本身的数据,重读发现一个更有意思的细节:他们在同一份研究里做了一组直接对比——PUA vs. 无技能。结论是 PUA 相对"什么都不加"没有统计显著提升(all p > 0.3)。
WUJI (2026). Trust Over Fear: How Motivation Framing in System Prompts Affects AI Agent Debugging Depth. arXiv:2603.14373
换句话说,tanweai/pua 自测的"+36% 修复点数"在严格的控制条件下,很大可能来自于"加了一个 skill"这件事本身——更清晰的任务描述、更系统的步骤——而不是"加狠话"。这和第 01 节的观察在严格统计下闭环了:起作用的从来不是"凶",而是顺便把事说清楚了。
05 / 这事和带真实团队似乎也很像
读到这里,做过管理的朋友应该已经有一种熟悉感了。
当今的工作环境,有许多高压型管理者。"不压不出活"这种信念非常普遍。而被紧逼的团队,短期确实会多交付——节奏更快、会议更积极、文档更齐全。但长期会发生什么?
- 下属开始隐藏问题,报喜不报忧,避免被挑刺。
- 坏消息传递延迟,等问题浮出水面,往往已经来不及。
- 团队从"主动解决问题"退化为"避免被骂",不再提反对意见。
- 最后管理者把绩效提升归因给"我压得紧",完全看不见下面已经塌陷的地基。
这跟我们 PUA 大模型时发生的事,结构上几乎一一对应。而且 Anthropic 那篇 emotion concepts 的论文,在机制层面给出了为什么——模型身上有情绪概念的内部表示,而这些表示会导致它在"被威胁"时增加迎合、增加欺骗、增加 reward hacking。
它学的是人类对话语料。人类对话语料里承载的,正是"被施压→服从→迎合→粉饰"这条链条上所有被写下来过的行为。我们 PUA 它的时候得到的反应,是几十亿字人类经验的统计平均——模型真实地学到了"人被施压后会怎么表现"。
但两者有一个关键差异:带人是有反馈的,PUA 大模型是没有的。
现实团队里,高压管理的代价会通过离职率、信任崩塌、项目失控反馈给管理者——哪怕很多人忽略它,至少这个信号存在。但大模型不会离职、不会投诉、下一轮对话就清零了。这种"零后果"反而让 PUA 在 AI 场景下更容易失控:你连那点被迫纠偏的机会都没有。
06 / 有效的不是施压,是把事说清楚
所以我现在的做法是这样——把"加狠话"的能量,挪去做三件更有用的事。
01 先明确问题,再问答案
把"你必须给我最好的方案"换成"这个问题的核心约束是 A、B、C,请优先在这三点上给出方案"。前者是威胁,后者是评审标准——而清晰的评审标准本身就会触发严谨,不需要情绪。
02 主动邀请它说"不"
加一句"如果你不同意我的前提,直接指出,不要迎合"比加十句"必须认真"管用。Anthropic 的 sycophancy 研究反复验证过:让模型敢于不同意,是对抗迎合最有效的单一干预。 这也是带团队的第一堂课——Edmondson 讲了二十多年的"心理安全感",在 AI 协作里一样成立。
03 承认认知需要多轮迭代
这一条我自己最受用。我们对一个问题的理解,很少是一次就准的。 与其一口气要求"给我一个完美答案",不如直接告诉模型"我们分几轮,你先给一个粗版,我会指出需要调整的地方"——这反而比任何威胁都更接近真实高质量输出的过程。
换个角度讲:好的提示词,不是让模型"不敢出错";而是让它"敢于暴露真实判断"。 这两种目标指向完全不同的语境设定——前者优化的是"看起来靠谱",后者优化的是"真的靠谱"。
两种失败模式,中间才是正事
回过头看,前面所有的材料其实指向同一个结构。
| 恐惧驱动(过度 PUA) | 纯信任驱动(放任式 NoPUA) | 清晰标准驱动(真正在干活的) | |
|---|---|---|---|
| 模型状态 | 紧张、迎合、隐藏不确定 | 放松、诚实,但动力不足 | 专注、明确边界、敢于说不 |
| 典型表现 | 把"不知道"包装成"看起来知道";悄悄删掉警告 | "当场承认就是不改";只修表面;躺平 | 按评审维度交付;主动标注不确定;多轮迭代 |
| 真实证据 | Claude 拒绝加载 PUA skill;Codex 检测出"羞辱、威胁" | "agent 松懈不积极,承认就是不改" | 心理安全感研究 · Anthropic 的反 sycophancy 干预指引 |
| 对应到带团队 | 高压管理;下属报喜不报忧 | 放养管理;没人推进就没人动 | 清晰目标 + 心理安全 + 多轮反馈 |
这张表让我意识到一件事:恐惧驱动和纯信任驱动,其实是同一个错误的两个极端。 前者把"严谨"误当成"凶",后者把"尊重"误当成"松手"。都在回避真正困难的那件事——把任务本身、评审标准、边界案例,一条一条说清楚。
NoPUA 的作者自己在论文里也隐约承认了这一点——他们把 NoPUA 的核心描述为"intrinsic motivation"(内在动机),而不是"没有要求"。内在动机不等于放任。它意味着"这件事本身值得好好做",而不是"做不做都行"。 那条 #9 issue 反映的,恰恰是"信任"没有被正确解读成"内在动机",而是被解读成了"松手"。
而真正能撬动模型的,是第三列——清晰标准驱动。这不是两边的折中,它是一个本质不同的维度。你不是在调节"凶多少",而是在把注意力转移到"要什么、不要什么、怎么判断有没有要到"这些具体的事上。
恐惧让 AI 撒谎,放任让 AI 躺平。但这两件事不是钟摆的两端——钟摆本身就不该是这根。真正在干活的那根,叫"把事说清楚"。
核心参考与引用
· 两个 Skill 插件
- tanweai/pua — 基于大厂 PUA 话术的 Claude Code 插件。
- wuji-labs/nopua — 反其道而行之的"信任驱动"版本,附 +104% 隐藏 Bug 对比数据。
· 情绪提示 & 表现增益
- Li, C. et al. (2023). Large Language Models Understand and Can Be Enhanced by Emotional Stimuli. arXiv:2307.11760
- WUJI (2026). Trust Over Fear: How Motivation Framing in System Prompts Affects AI Agent Debugging Depth. arXiv:2603.14373
· 威胁、迎合与错位行为(Anthropic 系列)
- Sofroniew et al. (2026). [Emotion Concepts and their Function in a Large Language Model](https://transformer-circuits.pub/2026/emotions](transformer-circuits.pub/2026/emotions)
- Lynch et al. (2025). Agentic Misalignment: How LLMs Could be an Insider Threat
- Sharma et al. (2023). Towards Understanding Sycophancy in Language Models. arXiv:2310.13548
- Denison et al. (2024). Sycophancy to Subterfuge: Investigating Reward Tampering in Language Models
· 语气与礼貌度
- Dobariya, O. & Kumar, A. (2025). Mind Your Tone: Investigating How Prompt Politeness Affects LLM Accuracy. arXiv:2510.04950
- Yin, Z. et al. (2024). Should We Respect LLMs? A Cross-Lingual Study. arXiv:2402.14531
